2023 프로메데우스 스타트업 해커톤 데이터 수집

Summary
- 대회 명 : 2023 프로메데우스 해커톤
- 대회 주제 : 시장성을 고려한 인공지능 활용 서비스 개발
- 대회 사이트 : https://aifactory.space/competition/detail/2241
- 팀 명 : 진지도
- 서비스명 : CPR(Connect Planet Recycle)
- 팀 아이디어 : 재활용 쓰레기 분리수거 서비스 개발
- “진지도” 해커톤 링크 : https://aifactory.space/competition/detail/2282
-
“진지도” 협업 기록 github README

Description
2023년 2월 한달간 진행한 프로메데우스 해커톤 관련 첫 포스팅 글입니다.
저는 이번 대회에서 재활용 쓰레기 분리수거 서비스 개발을 진행했습니다.
이 서비스는 제가 오래 전부터 생각했던 아이디어로, 드디어 서비스로 실현하게 되는 날이 오게 되어 뜻깊은 프로젝트 였습니다.
제가 맡은 과제는 프로젝트 총괄, 기획, 데이터 구축, 최종 파이프라인 구축, 1차 모델 개발입니다.
제가 사용하고자 한 데이터는 구글에서 구축한 이미지 데이터이며(raw_images), 이 데이터를 Roboflow에서 bounding box labeling 작업 후 data augmentation을 진행 하였습니다.
자세한 프로젝트 내용은 문의바랍니다.
workflow
- 데이터 구축
- 활용 사이트 : roboflow
- 1차 모델 개발
- object detection 활용
- 시도 모델 : yolov7, yolov8
- 최종 활용 모델 : yolov8
-
2차 모델 개발
- 최종 파이프라인 연결 및 구축
- 파이프라인 모듈명 : pipline
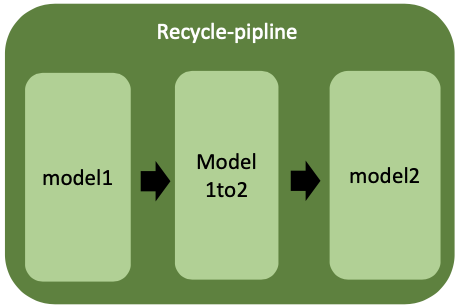
- 파이프라인 모듈명 : pipline
Contents
구글 크롤링을 시도했으나, 필요한 데이터의 수가 적고, 이미지 특성상 한국에 최적화된 아이디어로, 최적화된 키워드를 찾기 쉽지 않아 구하기 쉽지 않았습니다.
적당한 키워드를 입력하여 데이터를 구축하고 확인한 결과 오염도가 심해 데이터를 다시 정제해야 하는 작업이 번거로웠습니다.
그래서 구글링을 통해 사진을 직접 확인 후 다운로드하여 raw data(raw_images)를 구축하였습니다.
데이터 수집 1차 시도 : 데이터 크롤링
- 타깃 클래스 3개 : 종이 가방, 패트 병, 비닐 봉지
- 데이터
- 훈련 데이터 (2020~2022년도 기준)
- 검증 데이터 (2019~2020년도 기준)
- 테스트 데이터 (2018~2019년도 기준)
- 참고 사이트
1) 관련 모듈 설치
!pip install icrawler
2) 관련 모듈 임포트
import os
import icrawler
import datetime
from multiprocessing import Pool
from icrawler.builtin import GoogleImageCrawler
import glob
3) 데이터 크롤링 & 라벨링
파일 생성
for x in ['train_data','valid_data','test_data']:
add='/content/drive/MyDrive/recycle/'+x
os.mkdir(add)
훈련 데이터 구축
keywords=['배달음식쓰레기']
path='/content/drive/MyDrive/recycle/train_data'
for i in keywords:
# 폴더 안에 이미지 삽입
path1=path+'/'+i
os.mkdir(path1)
google_crawler = GoogleImageCrawler(
feeder_threads=1,
parser_threads=1,
downloader_threads=4,
storage={'root_dir': path1 })
filters = dict(
size='large',
color='orange',
license='commercial,modify',
date=((2020, 11, 30), (2022, 11, 30)))
google_crawler.crawl(keyword=i, filters=filters, offset=0, max_num=1000,
min_size=(200,200), max_size=None, file_idx_offset=0)
path2=path1+'/*'
image=glob.glob(path2)
for x,y in enumerate(image):
os.rename(y,os.path.join(path1+"/",f"{i}_"+"{0:06d}".format(x+1)+"."+y[-3:]))
검증 데이터 구축
keywords=['plastic bag','paper bag','pet bottle']
path='/content/drive/MyDrive/recycle/valid_data'
for i in keywords:
# 폴더 안에 이미지 삽입
path1=path+'/'+i
os.mkdir(path1)
google_crawler = GoogleImageCrawler(
feeder_threads=1,
parser_threads=1,
downloader_threads=4,
storage={'root_dir': path1 })
filters = dict(
size='large',
color='orange',
license='commercial,modify',
date=((2019, 11, 30), (2020, 11, 30)))
google_crawler.crawl(keyword=i, filters=filters, offset=0, max_num=1000,
min_size=(200,200), max_size=None, file_idx_offset=0)
path2=path1+'/*'
image=glob.glob(path2)
for x,y in enumerate(image):
os.rename(y,os.path.join(path1+"/",f"{i}_"+"{0:06d}".format(x+1)+"."+y[-3:]))
테스트 데이터 구축
keywords=['plastic bag','paper bag','pet bottle']
path='/content/drive/MyDrive/recycle/test_data'
for i in keywords:
# 폴더 안에 이미지 삽입
path1=path+'/'+i
os.mkdir(path1)
google_crawler = GoogleImageCrawler(
feeder_threads=1,
parser_threads=1,
downloader_threads=4,
storage={'root_dir': path1 })
filters = dict(
size='large',
color='orange',
license='commercial,modify',
date=((2018, 11, 30), (2019, 11, 30)))
google_crawler.crawl(keyword=i, filters=filters, offset=0, max_num=1000,
min_size=(200,200), max_size=None, file_idx_offset=0)
path2=path1+'/*'
image=glob.glob(path2)
for x,y in enumerate(image):
os.rename(y,os.path.join(path1+"/",f"{i}_"+"{0:06d}".format(x+1)+"."+y[-3:]))
데이터 수집 2차 시도 : 데이터 수작업
구글링으로 직접 데이터를 구축한 후 roboflow를 통해 데이터 라벨링 작업 진행 후 데이터 증강하였습니다.
라벨링하는 것이 귀찮긴 하지만 (어차피 기존의 데이터 사이트들에서 구축되어있지 않았던 데이터를 학습시키는 거라 직접 라벨링 작업 해야했음…) 코드짜기 귀찮을 때 매우 좋은 사이트인 것 같습니다.. 강추..!!
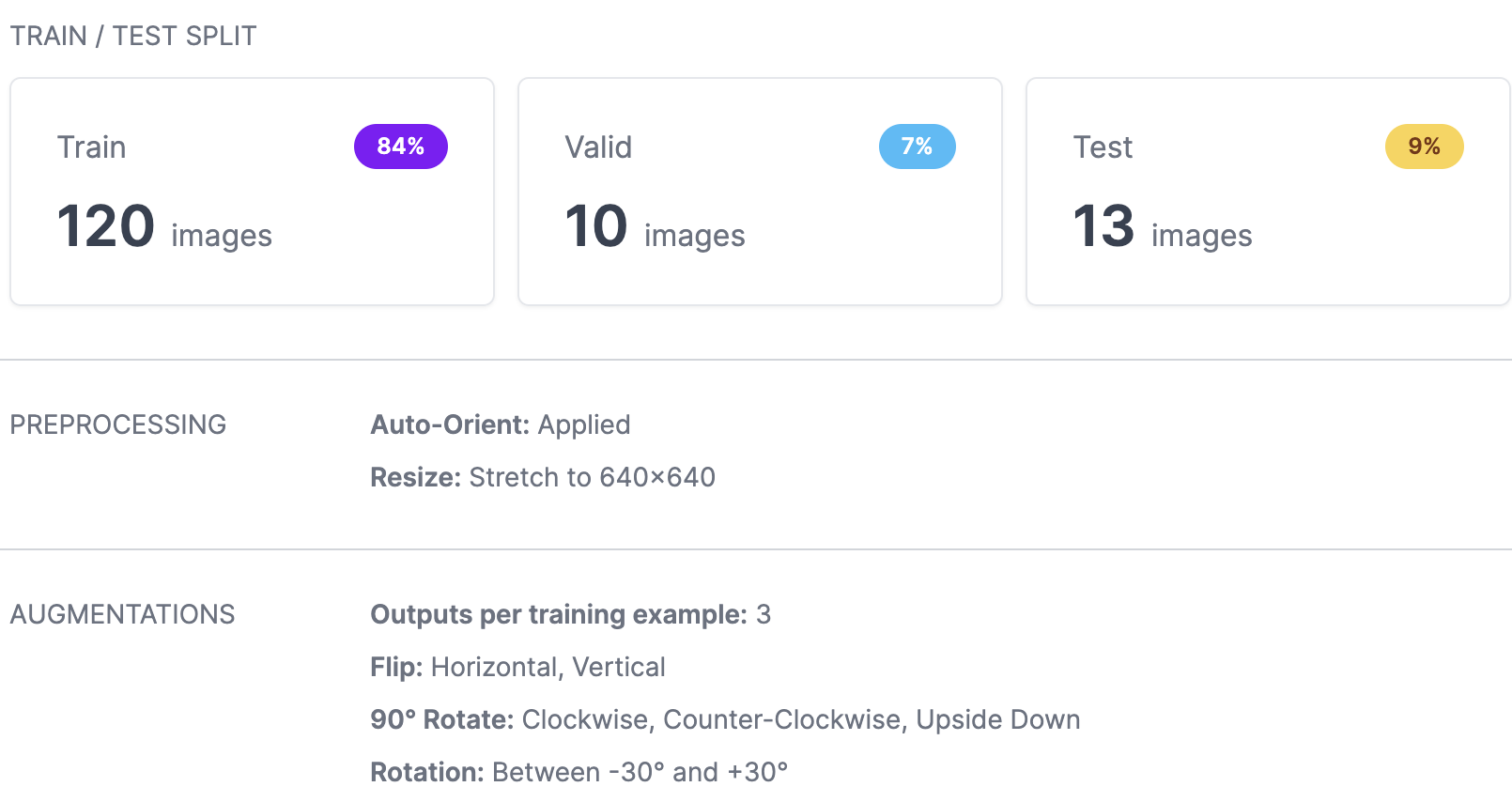
- 타깃 클래스 16개
- raw 데이터 개수 : 143개
- 데이터 증강 후 데이터 : 143 * 3 = 439개
댓글